[Python] 딥러닝, 오버피팅 확인법, 조기종료 방지
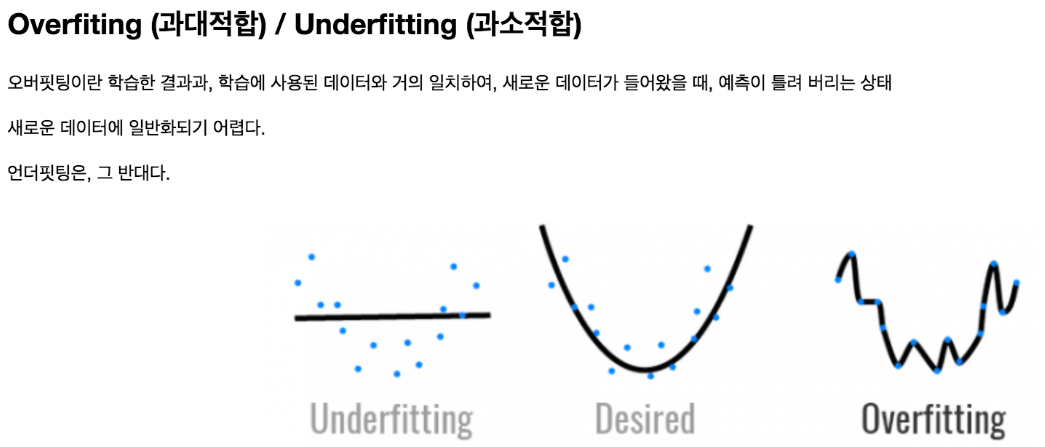
오버피팅(Overfitting, 과적합)
오버피팅은 머신 러닝 모델이 훈련 데이터에 너무 맞춰져서 새로운 데이터에 대한 일반화 성능이 떨어지는 현상이다. 똑같은 훈련 데이터를 너무 오래 학습하면 모델이 기존 훈련 데이터에 너무 맞춰 학습하다보니 새로운 데이터에 대한 일반화 능력이 떨어지는 현상을 나타낸다.

자동차 연비를 구해야 하는 데이터 프라임이 있다.
이 데이터를 전처리 과정(생략) 을 한 후에 Sequential 모델을 사용하여 신경망을 구축했다.
def build_model():
model=Sequential()
model.add(Dense(64, activation='relu',input_shape=(X_train.shape[1],)))
model.add(Dense(64,activation='relu'))
model.add(Dense(1,activation='linear'))
model.compile(optimizer= tf.keras.optimizers.Adam(learning_rate=0.001), loss='mse',metrics=['mae'] )
return model- Dense 레이어: 이 모델은 Fully Connected 레이어로 이루어져 있다. 첫 번째 Dense 레이어는 64개의 뉴런을 가지며 활성화 함수로 ReLU(Rectified Linear Unit)를 사용한다. 입력 형태는 X_train의 열의 수에 따라 결정된다. 즉, 입력 차원은 (X_train.shape[1],)이다.
- 출력 레이어: 마지막 Dense 레이어는 선형 활성화 함수를 사용하고 하나의 뉴런을 가진다. 이 레이어는 회귀 모델의 출력을 생성한다.
- 모델 컴파일: Adam 옵티마이저를 사용하여 모델을 컴파일한다. 손실 함수로는 평균 제곱 오차(Mean Squared Error, MSE)를 사용하고, 평가 지표(metrics)로는 평균 절대 오차(Mean Absolute Error, MAE)를 선택했다.
이 함수를 호출하면 위에서 정의한 모델이 만들어지고 반환된다. 이러한 모델 구조는 주어진 입력에 대해 선형적인 출력을 예측하는 간단한 신경망을 나타낸다.
model=build_model()
epoch_history=model.fit(X_train,y_train,epochs=100)build_model() 함수를 사용하여 모델을 생성하고, 생성된 모델을 사용하여 주어진 데이터(X_train, y_train)에 대해 100번의 에포크(epoch) 동안 훈련한다.

모델이 100번의 에포크를 실행해서 loss(모델의 예측값과 실제 타깃값 간의 차이를 나타내는 지표)와 mae( 평균 절대 오차 )를 출력한것을 볼 수 있다. loss와 mae는 오차를 나타내는 값이므로 수치가 작아질수록 학습이 잘됐다고 볼 수 있다.
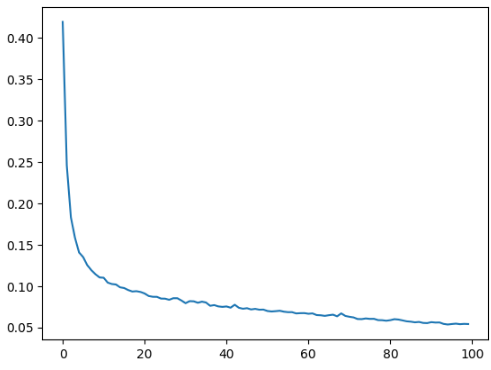
loss를 그레프를 이용하여 표시했을때 값이 작아짐으로 정확한 예측을 했다고 볼 수 있다
하지만 이 데이터는 똑같은 데이터, 즉 테스트용 데이터를 계속 돌린것이라 loss가 줄어든 것이지
우리가 실제로 예측할 임의의 데이터를 예측한것이 아니기때문에 세로운 데이터가 들어왔을때 정확하지 않을 수가 있다.
그럴떄 사용하는게 validation_split 이다.
validation_split은 데이터를 훈련 세트와 검증 세트로 분할하는 데 사용되는 매개변수이다. 보통은 이를 사용하여 전체 데이터셋에서 일정 비율(일반적으로 0.1에서 0.3 사이)만큼을 검증 세트로 분리한다.
예를 들어, validation_split=0.2로 설정하면 전체 데이터의 20%를 검증 세트로 사용하고 나머지 80%를 훈련 세트로 사용한다. 이렇게 하면 모델이 훈련 데이터에 과도하게 적합되는 것을 방지하고 일반화 성능을 더 정확하게 평가할 수 있다.
model=build_model()
epoch_history=model.fit(X_train,y_train,epochs=500,validation_split=0.2)#
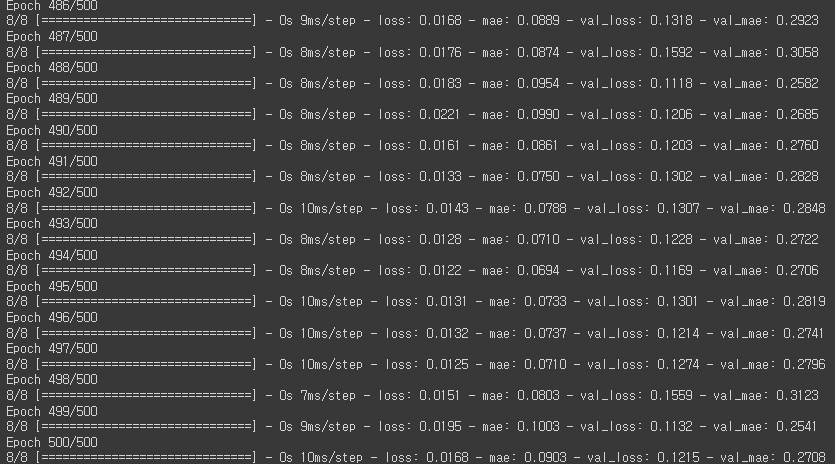
학습용 데이터와 검증용으로 불러온 데이터의 loss(val_loss)와 mae(val_mae)를 볼 수 있다.
학습용 데이터
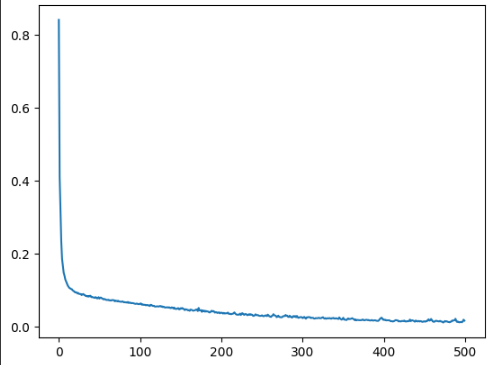
똑같은 데이터로 예측해서 오차가 계속 줄어든다.
훈련용 데이터

검증용 데이터로 모델을 돌려보니 특정값에서부터 loss값과 mae값이 튀기 시작한다.
이것을 오버피팅이라고 한다.
오버피팅된 모델로 세로운 데이터를 예측했을경우 정확한 예측이 안나올 확률이 높다.
이 그래프를 보면 수 백번 에포크를 진행한 이후에는 모델이 거의 향상되지 않는다. 검증 점수가 향상되지 않으면 자동으로 훈련을 멈추도록 만들어 보자.
에포크마다 훈련 상태를 점검하기 위해 EarlyStopping 콜백(callback)을 사용하겠다. 콜백을 사용하면 지정된 에포크 횟수 동안 성능 향상이 없으면 자동으로 학습을 멈춘다,.
early_stop=tf.keras.callbacks.EarlyStopping(monitor='val_loss',patience=10)
epoch_history=model.fit(X_train,y_train,epochs=100000,validation_split=0.2,callbacks=[early_stop])
TensorFlow안에 있는 ElarlyStopping을 사용해서 'val_loss'가 10번동안 감소하지않으면 멈추게 할 수 있다.
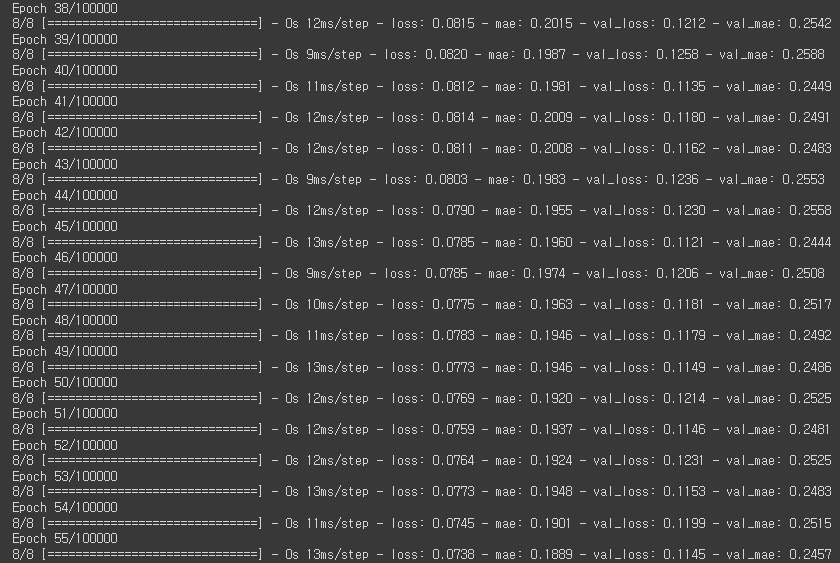
val_loss가 10번이상 감소하지않아 55번쨰 epoch에서 멈췄다.

출력 결과를 보면 콜백을 사용하기전보다 후가 val_loss가 안정적인 것을 볼 수 있다.