Machine Learning

머신러닝은 컴퓨터 시스템이 데이터에서 학습하고 경험을 통해 자동적으로 개선되는 알고리즘과 기술을 연구하는 인공지능의 한 분야이다. 이는 명시적으로 프로그래밍되지 않은 데이터를 사용하여 작업을 수행하도록 컴퓨터를 학습시키는 과학이다.
머신러닝 알고리즘은 대부분 다음과 같은 과정을 따른다:
- 데이터 수집: 머신러닝 모델을 학습시키기 위해 데이터를 수집한다. 데이터는 입력 변수와 해당 변수에 대한 결과(목표 값 또는 레이블)으로 구성된다.
- 데이터 전처리: 수집된 데이터를 정제하고 준비한다. 이 과정에는 데이터의 결측치 처리, 이상치 제거, 데이터 스케일링 등이 포함될 수 있다.
- 모델 선택: 주어진 작업에 가장 적합한 머신러닝 모델을 선택합니다. 이는 데이터의 유형, 작업의 목적 등에 따라 다르며, 회귀, 분류, 군집화 등의 다양한 유형의 모델이 있다.
- 모델 학습: 선택된 모델을 학습 데이터에 적용하여 모델을 훈련시킨다. 모델은 학습 데이터에서 패턴을 학습하고 입력 데이터와 해당 결과 사이의 관계를 파악한다.
- 모델 평가: 학습된 모델의 성능을 평가합니다. 이를 통해 모델이 새로운 데이터에서 얼마나 잘 작동하는지를 알 수 있다.
Regression(회귀)은 머신러닝의 한 분야로, 입력 변수와 출력 변수 간의 관계를 모델링하는 기술입니다. 회귀 모델은 주로 연속형 변수(실수 값)를 예측하는 데 사용된다.
연차별 급여가 있는 데이터를 보고 연차와 급여에 대한 인공지능을 만들어 급여를 예측하고 그 값이 정확한지 확인, 편차를 구해보자.
1.데이터수집

연차별 급여가 있는 데이터가 있다.
2.데이터 전처리
df.isna().sum()
#출력값:
YearsExperience 0
Salary 0
dtype: int64
데이터에 Nan이 있으면 안됨으로 Nan이있나 확인해준다.
y=df['Salary']
X=df['YearsExperience'].to_frame()
x랑 y랑 비교해야 하기때문에 x랑 y를 분리시켜준다. 여기서
X는 데이터프라임 형태로 해야하는데, 일반적으로 머신러닝 모델을 학습시키는 데에는 데이터프라임 형태가 유용하기 때문이다.
- 편리한 데이터 조작: 데이터프레임은 열(column)과 행(row)으로 구성된 테이블 형태의 데이터 구조를 가지고 있어 데이터를 쉽게 조작할 수 있다. 열은 특성(feature)을 나타내며, 행은 개별 데이터 포인트를 나타낸다. 이를 통해 데이터를 필요에 따라 변형하거나 선택할 수 있다.
- Pandas의 풍부한 기능 활용: 데이터프레임은 Pandas 라이브러리의 핵심 데이터 구조이며, Pandas는 데이터 조작 및 처리를 위한 다양한 기능을 제공한다. 따라서 데이터프레임 형태로 데이터를 사용하면 Pandas의 다양한 기능을 활용하여 데이터 전처리 및 분석을 수행할 수 있다.
- 모델링의 일관성 유지: 데이터프레임을 사용하면 모든 특성과 레이블을 하나의 객체에 포함시킬 수 있으므로 모델링 프로세스의 일관성을 유지할 수 있다. 이는 데이터 전처리, 모델 학습, 평가 등의 단계에서 유용하다.
y가 데이터프라임 형태일 필요가 없는 이유는 y사 일반적으로 예측하려는 대상이기 때문이다. 보통 y는 출력변수 또는 레이블로 사용되며, 모델이 예측하고자 하는 대상을 나타낸다.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=11)

Scikit-learn의 train_test_split 함수를 사용하여 데이터셋을 학습용과 테스트용으로 나누는 과정을 수행한다. 이 함수는 입력 데이터(X)와 출력 데이터(y)를 받아서 지정된 비율에 따라 두 부분으로 나누고, 학습용 데이터와 테스트용 데이터를 반환합니다. 여기서 사용된 매개변수들은 다음과 같다:
- X: 입력 변수로 사용될 데이터셋이다.
- y: 출력 변수 또는 레이블로 사용될 데이터셋이다.
- test_size: 테스트용 데이터셋의 비율을 나타내는 값이다. 여기서는 전체 데이터셋의 20%가 테스트용으로 사용되도록 설정되었다.
- random_state: 데이터를 분할할 때 랜덤 시드를 설정하는 값입니다. 이를 통해 동일한 결과를 재현할 수 있다.
위의 코드를 실행하면 X_train, X_test, y_train, y_test라는 네 개의 변수에 각각 학습용 입력 변수, 테스트용 입력 변수, 학습용 출력 변수, 테스트용 출력 변수가 저장된다. 이렇게 나뉜 데이터셋을 사용하여 모델을 학습하고 평가할 수 있다.
3. 모델 선택
Regression
어진 데이터를 이용하여 연속적인 값을 예측하는 데 사용되는 머신러닝 기법 에는 Regression 이 있다 .
Regression은 선형 회귀(Linear Regression) 으로 입력 변수와 연속적인 타깃 변수 간의 선형 관계를 모델링하는 데 사용된다. 연속형 변수인 연봉을 예측하는 데 사용되며, 간단하고 해석하기 쉬운 모델로서 널리 사용된다.
4.모델 학습
from sklearn.linear_model import LinearRegression
regressor= LinearRegression()
# 인공지능을 학습시킨다.
regressor.fit(X_train,y_train)
scikit-learn 라이브러리를 사용하여 선형 회귀 모델을 생성하고 학습시키는 과정을 보여준다.
여기서 X_train은 훈련 데이터의 입력 특성을 나타내는 데이터프레임이고, y_train은 해당 특성에 대응하는 타깃 값(연봉)을 나타낸다.
LinearRegression 클래스는 선형 회귀 모델을 구현한 것으로, 이를 사용하여 입력 특성과 타깃 값 간의 선형 관계를 모델링을한다. fit() 메서드를 호출하여 모델을 훈련 데이터에 맞춘다. 이를 통해 모델은 입력 특성과 타깃 값 간의 관계를 학습하게 된다.
따라서 위의 코드를 실행하면 선형 회귀 모델이 X_train과 y_train 데이터를 이용하여 학습되고, 훈련된 모델인 regressor를 얻을 수 있다.
5. 모델 평가
y_pred=regressor.predict(X_test)
학습이 끝나면, 이 인공지능이 얼마나 똑똑한지 테스트 해야 한다.
따라서 테스트용 데이터는 X_test 로 테스트 한다.

X_test는 y_test라는 정해진 연봉값이 있는데, 인공지능 모델이 측정한 값과 얼마나 차이가 나는지 오차를 확인할 수 있고 그 값을 y_pred로 저장한다.
mse
MSE (Mean Squared Error, 평균 제곱 오차 )는 회귀 모델의 성능을 측정하는 데 사용되는 일반적인 지표 중 하나다. 이것은 실제 값과 모델이 예측한 값 사이의 평균 제곱 차이를 나타내는 값이다.
error = y_test -y_pred
(error ** 2).mean()
#출력값:
31727520.866778105
mse를 구하는 공식은 (실제측정값 - 예측값)² / 평균값 이다.
성능을 측정하기 위해서는 오차를 제곱해서, 부호를 먼저 없앤 후에 평균을 구해야한다.
시각화
측정값과 예측값의 차이를 한눈에 보기위해 차트를 그려보겠다.
df_test = y_test.to_frame()
df_test['y_pred']= y_pred
df_test.reset_index(drop=True, inplace=True)
df_test.plot(kind='bar')
plt.show()
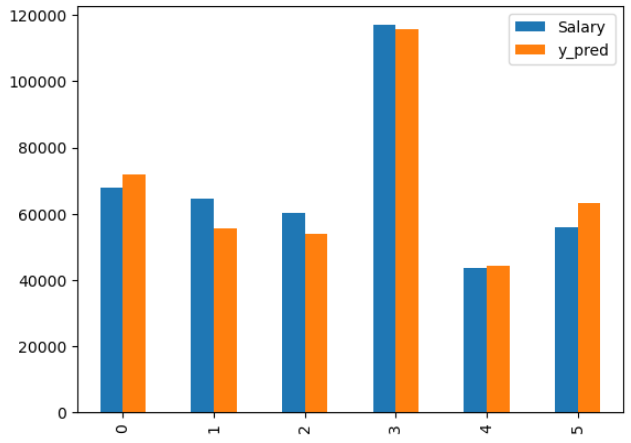
비교를 쉽게 하기위해 y_test 를 데이터프라임 형식으로 만들고 y_pred를 y_test에 추가시키고 bar형태의 그래프로 출력했다.
'AI > Machine Learning' 카테고리의 다른 글
| [Python]머신러닝 용어 정리 supervised, unsupervised 차이점, 종류 (0) | 2024.04.22 |
|---|---|
| [Python] Logistic Regression 이진 분류, 예측 (0) | 2024.04.15 |
| [Python]머신러닝 Machine Learning MSE(평균 제곱 오차,Mean Squared Error ) 를 쓰는 이유 (1) | 2024.04.12 |


