데이터 전처리
데이터 전처리는 데이터를 분석하고 모델링하기 전에 데이터를 정제하고 준비하는 과정을 말한다. 이는 데이터의 품질을 향상시키고 모델의 성능을 향상시키는 데 중요한 단계이다.
.
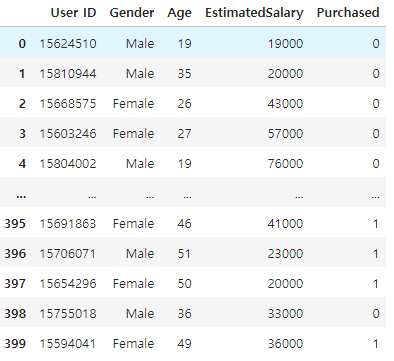
나이와 연봉을 이용하여 물건을 구매할 사람인지 아닌지 예측하는 데이터(df)가 있다.
데이터 가공을 하기위해 데이터에 누락된 값( Nan) 이 있는지 확인해보자.
df.isna()
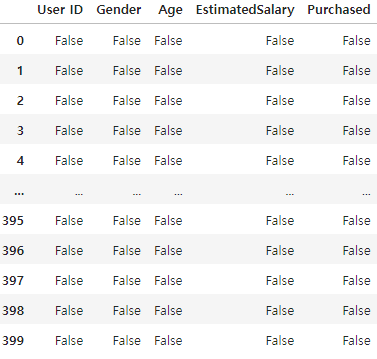
isna()는 데이터에 Nan이 있으면 True로 출력한다.
df.isna().sum()
#출력값
User ID 0
Gender 0
Age 0
EstimatedSalary 0
Purchased 0True는 1임으로 sum()을 통해 더해서 1의 갯수를 확인한다.
여기선 nan이 없었지만 있다면 dropna()를 사용해 nan 데이터의 행을 지워준다.
y=df['Purchased']구매했는지 예측하기위한 정보인 'Purchased'를 y로 저장한다.
X=df.loc[:,'Age':'EstimatedSalary']
구매 예측을위한 정보인 Age , EstimatedSalary 만 X로 저장하고 나머지는 버린다.
피쳐스케일링
피쳐 스케일링은 데이터 분석 및 모델링에서 중요한 단계이다. 다음은 피쳐 스케일링을 하는 이유이다:
- 모델 성능 향상: 특성의 스케일이 다르면 모델이 특정 특성에 지나치게 영향을 받을 수 있다. 예를 들어, 한 특성의 범위가 크고 다른 특성의 범위가 작다면, 모델은 범위가 큰 특성에 더 큰 중요성을 부여할 수 있다. 이로 인해 모델의 성능이 저하될 수 있다. 피쳐 스케일링을 통해 이러한 문제를 해결하고 모델의 성능을 향상시킬 수 있다.
- 모델 수렴 속도 개선: 몇몇 머신 러닝 알고리즘은 특성의 스케일에 민감하다. 특성의 스케일을 조정하면 모델이 더 빠르게 수렴할 수 있다. 특히 경사 하강법과 같은 최적화 알고리즘에서는 특성의 스케일을 조정함으로써 수렴 속도를 개선할 수 있다.
- 이상치 영향 완화: 특성의 스케일이 다르면 이상치(outlier)가 모델에 미치는 영향이 커질 수 있다. 피쳐 스케일링을 통해 이상치의 영향을 완화할 수 있다. 특히 표준화(Standardization)는 이상치의 영향을 상대적으로 줄일 수 있다.
StandardScaler , MinMaxScaler 둘중 하나 선택해서 사용
StandardScaler 사용법
from sklearn.preprocessing import StandardScaler
scaler_X = StandardScaler()
X=scaler_X.fit_transform(X)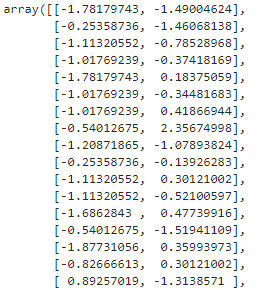
StandardScaler는 데이터의 특성을 평균이 0이고 표준 편차가 1이 되도록 변환하는 전처리 도구이다. StandardScaler는 데이터의 각 특성(feature)을 독립적으로 변환하여, 각 특성이 같은 스케일을 가지도록 만들어준다.
*각 특성의 평균을 빼고 표준 편차로 나누어 특성의 평균이 0이 되고 표준 편차가 1이 되도록 변환한다.*
이제 정제된 데이터인 X와 y를 가지고 기호에 맞게 모델을 사용할 수 있다.
MinMaxScaler 사용법
from sklearn.preprocessing import MinMaxScaler
scaler_X = MinMaxScaler()
X=scaler_X.fit_transform(X)
MinMaxScaler는 데이터의 특성을 주어진 범위로 조정하는 전처리 도구이다. 주어진 범위는 일반적으로 [0, 1] 또는 [-1, 1]로 설정된다. MinMaxScaler는 데이터의 각 특성을 최소값과 최대값 사이의 범위로 선형 변환하여 조정한다. 각 특성의 최소값을 0으로, 최대값을 1로 변환하여 스케일링한다.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y, test_size=0.25,random_state=1)데이터셋을 훈련용과 테스트용으로 나누기 위해 scikit-learn의 train_test_split 함수를 사용한다.
- X: 데이터셋에서 특징 또는 독립 변수이다.
- y: 데이터셋에서 목표 또는 종속 변수이다.
- test_size=0.25: 이 매개변수는 테스트 분할에 포함할 데이터셋의 비율을 지정한다. 여기서는 데이터의 25%가 테스트에 사용되고 나머지 75%가 훈련에 사용된다.
- random_state=1: 이 매개변수는 무작위 시드를 설정하여 데이터 분할을 재현 가능하게 만든다. 특정 값(여기서는 1)으로 설정하면 동일한 입력 데이터로 코드를 실행할 때마다 동일한 출력 분할을 얻을 수 있다.
이 코드를 실행한 후에는 네 종류의 데이터가 생성된다:
- X_train: 모델을 훈련하기 위해 쓰이는 데이터이다.
- y_train: 모델을 훈련하기 위해 쓰이는 데이터이다
- X_test: 학습된 모델을 테스트 해보기 위해 쓰이는 데이터로 모델에 따라 예측값을 출력한다.
- y_test: X_test에 대한 y값으로 X_test를 사용해서 얻은 예측값과 비교하기위해 사용되는 데이터이다..
이 후 여러가지 모델을 사용해 예상 데이터를 뽑을 수 있다,
'AI' 카테고리의 다른 글
| [Python]Deep Learning 딥러닝 인공지능 이해 머신러닝 차이점 (0) | 2024.04.16 |
|---|
