1. index, 컬럼 데이터로 저장하기

df라는 변수에 14000개의 데이터가 저장되잇는 Dataframe이 있다.
1. 인덱스를 title 컬럼으로 셋팅하라.
df.set_index('title', inplace=True)
print(df)
title의 데이터가 index로 이동했다.
2. 새로운 컬럼 추가하는법
리뷰에 새로운 컬럼 critic 만들고, everyone 이라고 값 넣어라.
df['critic'] = 'everyone'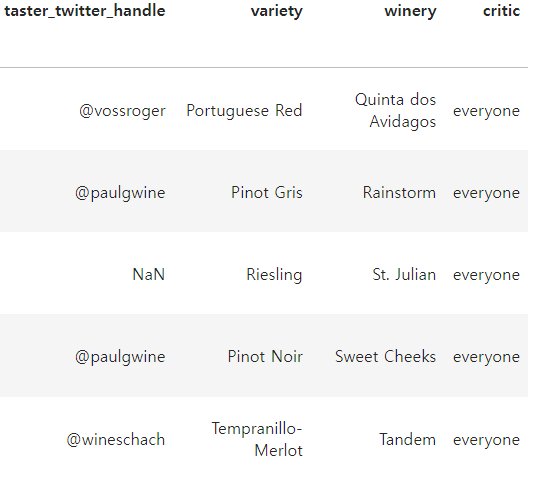
우측에 critic 이라는 컬럼이 생겼고 모든 값에 'everyone'이 들어갔다.
3. 연산을 통한 데이터 추출
리뷰의 포인트의 평균을 구하고, 리뷰의 포인트값이, 평균보다 큰 데이터 (즉, 평가가 좋은 와인) 만 가져오시오.
df['points'].mean()
#출력값
88.44713820775404
array를 기반으로 한 라이브러리임으로 mean()을 써서 평균값을 알 수 있다.
df['points'] > df['points'].mean()0 False
1 False
2 False
3 False
4 False
...
129966 True
129967 True
129968 True
129969 True
129970 Truedf[ 'points' ] 가 평균을 넘을시에 True를 출력한다.
df.loc[df['points'] > df['points'].mean() , :]
df[ 'points' ] 의 행이 True값만 찾아서 열을 모두 출력한다.

points가 88.44713820775404 가 넘는 값만 출력된걸 볼수 있다,
'Python > Project' 카테고리의 다른 글
| [Python] Pandas Dataframe 예제.(인덱스 재정렬, 상위 n개 데이터 출력 ,str.contains ,str.startswith,isin, ~ False만 출력) (0) | 2024.04.09 |
|---|---|
| [Python]Pandas 예제. (unique, apply , groupby) (0) | 2024.04.08 |

