DataUrl = 'https://raw.githubusercontent.com/Datamanim/pandas/main/chipo.csv'
df = pd.read_csv(DataUrl)

4000개의 식당데이터를 Dataframe형식으로 블러와 df로 저장한다.
1. quantity컬럼 값이 3인 데이터를 가져와서, index를 0부터 정렬하고 첫 5행을 출력하라.
1.
df['quantity'] ==3, # quantity 값이 3인 값 출력
2.
df.loc[df['quantity'] ==3, ] # quantity 값이 3인값의 행까지 출력
3.
df.loc[df['quantity'] ==3, ].reset_index().head() # 인덱스값을 리셋하고 상위 n개값(기본값 5개)만 출력
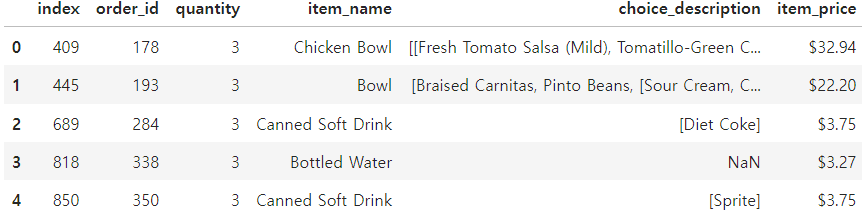
.
.str.contains()
.str.contains() 은 문자열을 포함하는지 여부를 확인하는 메서드이다. 이 메서드를 사용하여 각 요소가 특정 문자열 패턴을 포함하는지 여부를 확인할 수 있다.
~
~ 는 파이썬에서 비트 단위 반전 연산자이다. Pandas에서는 불린 인덱싱을 사용할 때 조건을 부정하는 데에도 사용된다.
2. df의 데이터 중 choice_description 값에 Vegetables 들어가지 않는 경우의 갯수를 출력하라
df['choice_description'].str.contains('Vegetables', na=False)
'choice_description' 컬럼을 불러오고 . 'Vegetable' 이 들어간 문자열이 포함된 값을 찾아 True를 출력한다.
~(df['choice_description'].str.contains('Vegetables', na=False))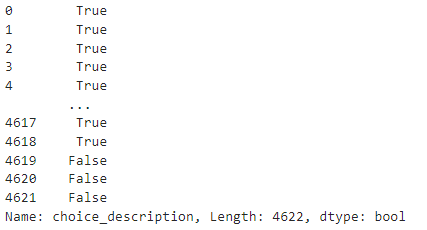
앞에 ~ 를 붙이면 True , False 값이 반대로 되는걸 볼 수 있다.
(~(df['choice_description'].str.contains('Vegetables', na=False))).sum()
#출력값
3900
True는 1로 처리됨으로 모든 수를 더하면 'Vegetables' 이 들어가지 않은 값의 총합을 알 수있다.
'Python > Project' 카테고리의 다른 글
| [Python]Pandas 예제. (unique, apply , groupby) (0) | 2024.04.08 |
|---|---|
| [Python] Pandas DataFrame예제. index 변환, 컬럼 추가, 연산을 통한 데이터 추출 (0) | 2024.04.08 |

